KWDB 时序引擎核心能力——存储与读写

K小二
本期直播我们邀请到 KaiwuDB 高级研发工程师管延信为大家分享《揭秘 KWDB 时序引擎核心能力——存储与读写》,点击下方视频观看完整版回放 ↓↓↓
https://mp.weixin.qq.com/s/ibuIZdazEqPPo7KtZGiN7g
📍以下重点内容节选,建议配合视频观看更佳。
背景介绍
在数字化浪潮席卷的万物互联时代,物联网设备与智能应用正以指数级速度催生海量时序数据。突破数据存储瓶颈、实现高效快速查询,已成为企业构建数据基础设施的关键议题。本次直播我们重点剖析了 KWDB 时序标签存储模型,从底层存储架构的优化策略到时序 SQL 语法语义的设计逻辑,从高性能读写功能的技术实现到复杂查询场景的应对方案,全方位带领大家了解 KWDB 如何实现数据的高速写入与毫秒级查询,助力高效数据管理。
1. 时序数据定义及特征
1.1 时序数据定义
时序数据(Time Series Data)是指按照时间顺序记录的数据序列,其中每个数据点都有一个时间戳。该类型数据在各领域都非常常见,如金融(股票价格)、气象(每日温度)、工业(传感器数据)等。
时序数据的主要特点是以时间为索引,数据点之间存在时间上的连续性和相关性,采集频率存在高低差异。
这些时序数据一般被发送至服务器进行汇总并进行实时分析和处理,对系统的运行做出实时监测或预测、预警,这些数据也可以被长期保存下来,用以进行离线数据分析。
1.2 时序数据特征
• 数据是时序的,带有时间戳。
• 数据是结构化的。
• 写多读少。
• 数据较少有更新删除操作。
• 一个数据采集点就是一个数据流。
• 一般是周期性产生/采集数据。
• 数据是有保留期限的。
• 需要实时分析、预测、诊断。
• 也需要离线分析能力。
• 数据不强制依赖于事务。
2. KWDB 时序数据存储模型
2.1 标签数据(如设备信息)与指标数据(如测量值)独立存储
• 节省存储空间(大量冗余 vs 持续变化)。
• 独立索引设计(Hash & B+ 树 vs 稀疏)。
• 独立并发控制机制(数据一致性 vs 尽量无锁)。
2.2 按设备与时间维度自动对指标数据分区
• 支持高效写入与查询。
• 灵活的生命周期管理机制。
• 分布式节点间快速均衡。
2.3 分区内数据按设备分块存储,避免大量文件产生
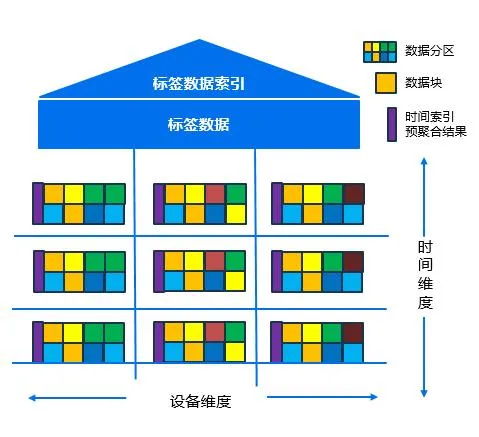
3. KWDB 标签分类与使用策略
3.1 主标签(Primary Tags)
• 定义规则:每个表必须包含至少 1 个主标签,且创建后不可修改。
• 典型场景:设备唯一标识(sensor_id)、用户 ID、资产编号等。
• 设计建议:
• 选择离散值高的字段(如自增 ID)。
• 避免使用可能变更的字段(如手机号)。
• 控制主标签数量(通常 1-4 个)。
-- 创建含复合主标签的表CREATE TABLE smart_meter (
ts timestamptz NOT NULL,
power_usage FLOAT
) TAGS (
region VARCHAR(6) NOT NULL,
meter_no BIGINT NOT NULL
) PRIMARY TAGS (region, meter_no);
3.2 普通标签(Tags)
• 动态管理:支持增删改操作,适合业务变化场景。
• 典型应用:
• 设备分组(group_id)。
• 设备型号(model_type)。
• 维护人员(maintainer)。
-- 动态维护标签示例ALTER TABLE sensor
ADD TAG firmware_version VARCHAR(20); -- 新增固件版本标签 ALTER TABLE sensor
ALTER TAG firmware_version TYPE VARCHAR(50); -- 修改标签类型 ALTER TABLE sensor
RENAME TAG group_id TO cluster_id; -- 重命名标签 ALTER TABLE sensor
DROP TAG location; -- 删除标签
3.3 KWDB 时序数据写入
• 可以通过 insert 自动创建对应设备。
• 减少标签数据冗余存储。

4. KWDB 索引优化实战
4.1 主标签的 Hash 索引
KWDB 自动为主标签创建 Hash 索引,针对精确查询实现 O(1) 时间复杂度:
-- 高效查询示例
SELECT * FROM sensor
WHERE sensor_id = 1005;
4.2 普通标签索引策略
4.2.1 对于高频查询的非主标签,建议手动创建索引:
-- 创建普通标签索引
CREATE INDEX idx_sensor_group ON sensor (group_id);
-- 带过滤条件的查询
SELECT * FROM sensor WHERE group_id = 10;
4.2.2 索引选择原则:
• 对查询频率高的标签建索引。
• 优先为高筛选率的字段建索引。
• 组合索引字段不超过 4 个。
4.3 KWDB 标签索引优势
• 可通过 insert 自动创建对应设备。
• 无需通过子表方式管理设备。
• 减少标签数据冗余存储。
• 支持在线标签 DDL 变更。
• 支持在标签上创建索引。
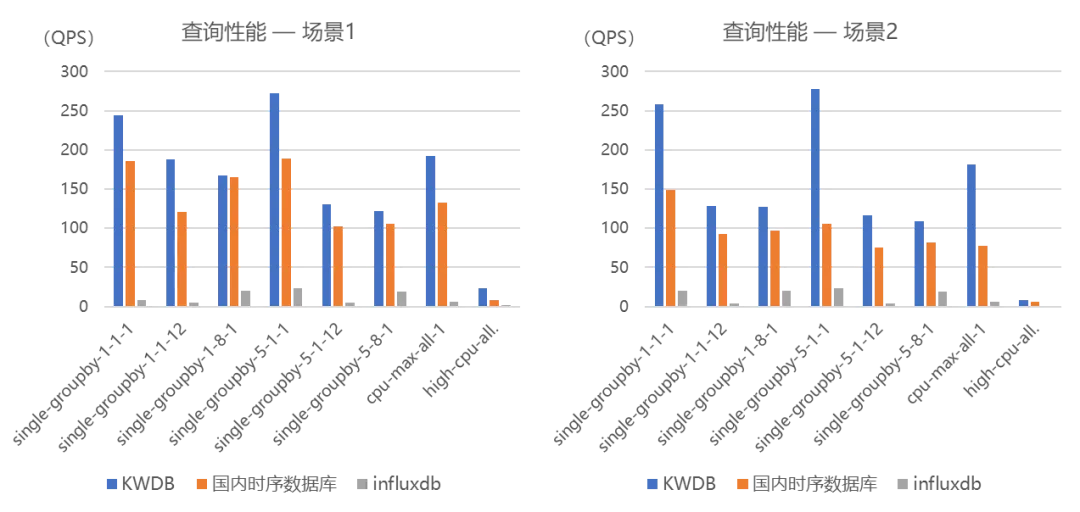
4.4 KWDB 2.0 性能表现
• 依托就地计算,单设备查询多设备汇总均有出色表现。
• 单节点实时写入支持 50 万测点/秒, 批量写入支持千万测点/秒,TSBS 基准写入速度 200 万记录/秒。
• 多数场景数据压缩比 5-30 倍。