

多模一库——架构简化,能力翻倍

K小二
何为多模?
"多模数据库"这个词在如今的数据库领域里,已经不再是个新鲜词。所谓多模数据库:目标是通过 "整合与效率 "解决传统 "单一模型数据库" 的局限性,用一个系统统一管理多种结构的数据,支持统一查询接口(如一套 SQL 扩展),减少数据同步和跨库操作的成本。它把多种数据库(如 MySQL、MongoDB、Influxdb)的能力整合到一个系统里,让用户不用为不同结构的数据搭建多个数据库。
什么场景需要多模?
举个例子,企业要存工厂设备类型信息(关系型)以及工厂各类设备(如拧紧机等)采集的数据(时序型),如果用 2 个独立数据库,会面临数据孤岛、跨库查询复杂、维护成本高的问题。而 KaiwuDB 作为国内面向物联网 AIoT 场景的分布式多模数据库代表,能够支持在同一实例同时创建时序库和关系库,融合处理包括结构化数据、非结构化数据在内的多模数据。KaiwuDB 通过单一数据库系统统一管理时序数据和关系数据,一库代替多库,从而实现技术架构的简化,并帮助客户降低开发和运维复杂度及成本。

KaiwuDB一库代替关系库+时序库
KaiwuDB 3.0 多模融合的内核
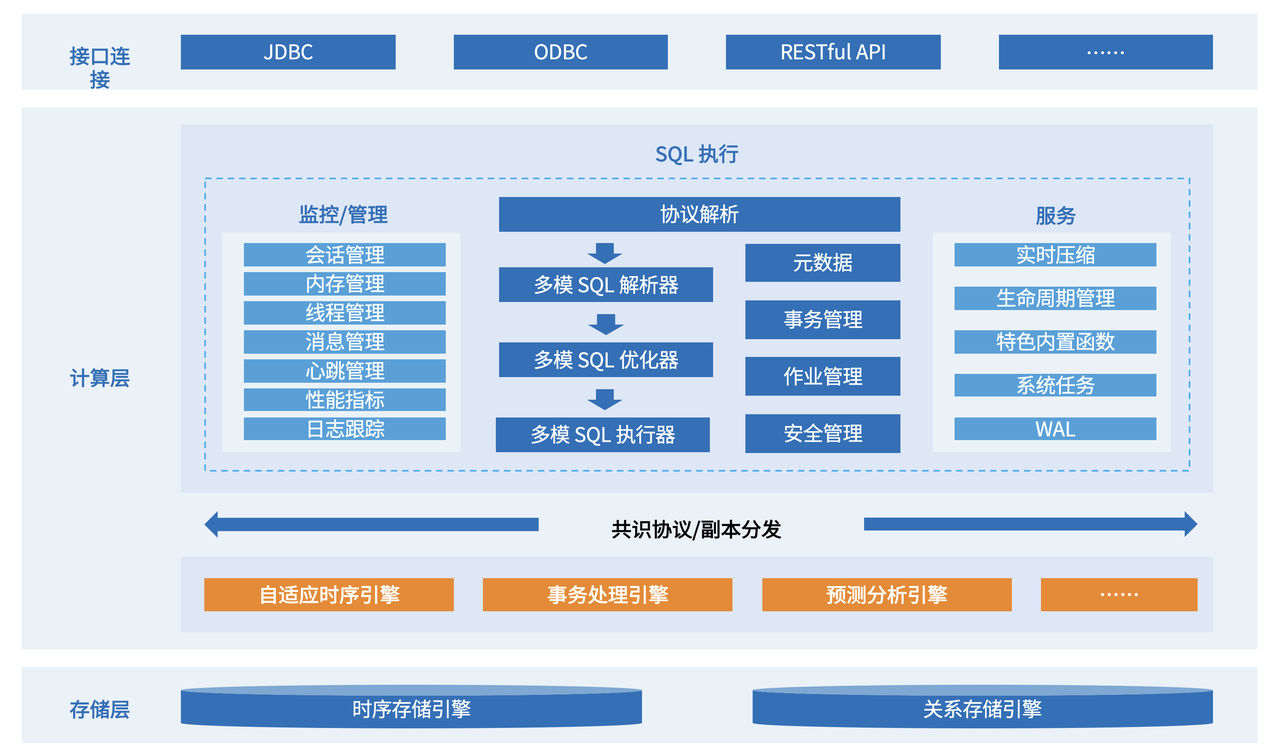
KaiwuDB 多模架构图
1. 接入层:多源数据统一收敛
• 协议兼容:JDBC/ODBC(关系数据)、RESTful API(时序 / 流式数据)、MQTT(IoT 设备直连)。
• 多模透明性:应用无需感知底层数据模型,统一接口适配时序 / 关系 / 非结构化 数据写入。
2. 解析优化层:跨模型查询语句解析、编译与优化
• 多模 SQL 处理:
① 解析器:兼容标准 SQL + 时序扩展语法(如 time_bucket 函数、窗口函数)。
② 优化器:自动识别数据模型(时序 / 关系),匹配最优执行路径。动态生成跨模执行计划,支持两种核心优化策略,跨模查询性能提升 5 倍以上。
-
Outside-In:当关联查询中的关系数据量较少时,关系数据过滤后下推至时序引擎。
-
Inside-Out:当关联查询中的时序数据量较少时,时序数据过滤或预聚合后返回到关系引擎进行关联。
• 元数据管理:统一管理时序库(TS DATABASE)与关系库元数据,支持跨模关联索引。
3. 计算引擎层:模型自适应执行
• 专属跨模计算算子,支持亿级时序数据与千万级关系数据秒级关联(如设备状态时序表 JOIN 设备属性表)。
• 专属单设备数据扫描算子,增加单设备跨模查询性能。
• 算子内并行,提升扫描和聚合性能。
• 聚合计算下推到时序引擎,从源头端压降数据量。
4. 存储管理层:混合架构适配
• 分层存储策略:
① 成本优化:通过冷热介质差异化存储,降低整体存储成本 30%~60%(时序场景下,冷数据占比通常 > 80%)。
② 性能保障:热数据留存于高速介质,确保实时业务(如监控告警、实时报表)的低延迟需求。
③ 灵活适配:支持自定义冷热规则、迁移策略与归档周期,适配 IoT 监控、工业日志等不同场景。
• 多模适配机制:
| 数据类型 | 存储结构 | 核心技术 |
|---|---|---|
| 时序数据 | 列式存储 | 自研压缩算法、就地计算技术、自研"主键标签"机制 |
| 关系数据 | 行式存储 + 主键索引 | 分布式事务、并行计算技术 |
5. AI 扩展层(多模增强)
支持 TensorFlow/XGBoost 模型全生命周期管理,可直接通过 SQL 调用模型推理,实现 "数据存储 - 训练 - 预测" 一体化。
核心功能特性&价值
• 一体化数据管理
通过单一数据库系统统一管理时序数据和关系数据,可以简化技术架构,降低开发和运维复杂度及成本。
• 高效时序数据处理能力
针对时序场景,自研"主键标签"机制,内置时序特色函数,提升数据库的读写性能;百万级 / 秒写入、毫秒级查询响应,支持 400 万 + 测点实时接入。
• 跨模查询
原生跨模关联查询,一套标准 SQL 操作两种数据,无需数据迁移。3.0 通过增加高效跨模连接算子,时序算子并行处理优化,跨模查询性能提升 5-10 倍。
• 资源与成本优化
避免异构数据库间的数据同步 ,减少数据冗余;通过计算下推,减少网络传输,降低数据处理时延。
• AI 深度赋能
① DB For AI:内置预测分析引擎,支持 SQL 级模型全生命周期管理,通过内置函数实现数据价值主动挖掘。
② AI For DB:提供 Agent 智能体工具,借助 MCP 协议,结合 LLM 技术,将自然语言处理与 KaiwuDB 深度结合,赋能数据库自动化运维与智能管理。